
Not interested in the back story? Jump ahead to Introducing Localizer.
Before we get into the details of what localizer is and how it came to be, it's crucial that we look at what developer environments were and the motivations behind the ones I create.
What is the Goal of a Developer Environment?
Ever since I wrote my first ever developer environment for the now-defunct StayMarta, I've always focused on one thing: ease of use. For a docker-compose based development environment, this was a relatively simple task. Create Docker containers, write a compose file, declare ports, and they'd be available on my local machine. It was as simple as docker-compose up. While this approach didn't necessarily match what production looked like, it was really the best option available for containers at the time. Options that exist now, such as Kubernetes, weren't available, which rendered equality between production and development a work-in-progress dream.
The Need to Scale
Fast forward to 2017, at my first larger-scale startup, Azuqua, I had a chance to reimagine what a developer environment looked like under a whole new set of constraints. While Docker Compose works for small teams, it falls apart when you map it to production systems. At the time, our production system was based on Chef. Docker Compose doesn't map to Ruby-based Chef configuration files. When I joined Azuqua, the pain around having separate tooling for infrastructure had become incredibly clear. It wasn't sustainable to have an entire team; write the configuration for our services, communicate with developers why infrastructure can't infinitely scale without good software design, and do it all without blame or single points of failure. Fundamentally this is why I take issue with DevOps teams and prefer promoting the Google SRE Model instead. While at Azuqua, we started a transition to an SRE model and used Kubernetes as a way to help facilitate that.
Introducing Kubernetes

While at Azuqua, I identified the need to run Kubernetes to ease cloud resources' scalability and improve the developer experience. At the same time, this drastically decreased the developer experience. While this may seem contradictory at first, it's essential to consider the multiple ways that developer experience presents itself. While at first, it may seem like it's just tooling to test/write code, it's a combination of testing code, writing code, and deploying that code. With the Docker Compose environment at StayMarta, we made the test/build cycle incredibly simple but shifted the deploy aspects onto a bespoke team, the DevOps model. That approach works for small teams, but as you grow, this quickly doesn't scale. If you can't deploy code efficiently, the developer experience is frustrating and promptly turns to an unhealthy relationship with the team responsible for that cycle.
So, how exactly does Kubernetes make this better then?
Going back to how Kubernetes improved the developer experience, which I assure you it does. The benefit to Kubernetes was that it brought a control plane into the mix and focused on being just a container orchestrator. The DSL it does have is highly specific to orchestrating containers and making them work. The control-plane allows self-healing and building tooling to enable all different types of use-cases consistently. While it lacks abstractions, it brings something to developers they've never had before, the ability to deploy code reproducibly. With the introduction of minikube, KinD, and others, you could now run the same stack you run in production, but locally.
The ability to reproducibly deploy helps both deployment confidence and the amount of time needed to get from nothing to running in production. However, it's not without its faults. Whenever you start moving deployment tooling onto developers, you've decreased the developer experience. It's unavoidable because you're introducing net new materials, DSLs, and more for the developers to learn. While KinD and minikube are great projects, they all suffer from needing developers to understand how to work with Kubernetes. You need to be able to build a Docker image, push the docker image into the cluster, delete the application pod, verify if it's even using the correct tag, wait for Kubernetes to recreate the container, and make sure you've configured an ingress route to access it outside of your cluster or use kubectl port-forward to access it. The second that breaks, you're now required to dig into why service connectivity isn't working, why your Docker image isn't in the containerd cache, or other not so easily solved areas. While to someone who's worked with Kubernetes for years now, this isn't very difficult, this is hardly achieving the "ease of use" goal I have.
How do we make a Kubernetes developer environment easier to use?
Solving these problems is not easy. Debugging Kubernetes is difficult and requires knowledge that can only be solved with education, more tooling, or a combination of both. Unfortunately, these are not cheap. Education is hard to do correctly and tends to result in lots of time writing quickly out of date material that is hard to maintain. While at Azuqua, we encountered this same problem. Very few engineers wanted to learn Kubernetes or invest time in the technology around it. We decided to go back to the basics and focus on a tooling based approach. How do we get the same developer experience level, at a minimum, of Docker Compose with Kubernetes? Our answer ended up being a tool called Telepresence. Telepresence describes itself as:
[...] an open source tool that lets you run a single service locally, while connecting that service to a remote Kubernetes cluster.
https://www.telepresence.io/discussion/overview
It seemed perfect, a tool that enabled your local machine to act as if it were running in Kubernetes and allow your services to be targeted from inside of Kubernetes. We rolled it out at Azuqua after initial tests showed it worked well, and we went with it. Unfortunately, it didn't last.
The Problem With Current Local Service Development Tooling
While Telepresence solved the problem of communicating with our local Kubernetes cluster, it spectacularly failed at letting services inside the cluster talk to our local services. When it worked, it worked amazingly, but nine times out of ten, it'd fail in a magnitude of ways. Whether that's failing to clean up after random crashing or slowly taking down the computer's internet connection, it generally wouldn't work. Luckily for us at Azuqua, we had a pretty well-defined system for service discovery and few services that needed to talk to one another directly. The few that needed that could just run outside of the cluster. That allowed us to accept those pains and be successful with Telepresence. To be clear, this is not a hit on Telepresence. It worked very well for us at Azuqua, but it's not a complete solution.
When I started developing a new development environment for Outreach, I again tried to use Telepresence as the solution to bridge the gap between our local cluster and our local machine. Unfortunately, it didn't work. We did not have a well-defined service discovery mechanism to work around the bugs, we had a much larger engineering team, and almost all services needed to talk to each other. We found more and more edge cases with Telepresence, and our developer experience was suffering. Our NPS score for our developer environment was at a low of -26, just because of Telepresence!
It was pretty clear that Telepresence was not going to solve our use-cases. It was time to look into alternatives.
What are other alternatives out there?
Telepresence was interesting since it used a VPN to give you access to your resources. However, it also required a hack DNS injector component, which tended to be the primary source of network problems. There weren't many projects out there that seemed to solve this, but one interesting one was kubefwd. If you're not aware of Kubernetes port-forwarding, there is a command that allows you to bring down a set of ports for a given service and have them be available on your local machine via kubectl port-forward. Think of the -p argument to docker run, but for Kubernetes. Unfortunately, this didn't support FQDNs (.svc.cluster.local), statefulsets, or all namespaces automatically. It also didn't support reverse tunneling. I wanted to keep the spirit of Telepresence by continuing to be a one-stop tool. Aside from kubefwd, there were seemingly no tools that could do this. Reverse tunneling into Kubernetes alone seemed to be an unsolved problem. To fill that gap, I decided to write localizer.
Introducing Localizer
Localizer is a rewrite of Telepresence in Golang, but without the complex surface area. Its goal is to be a simple, no-frills development tool for application developers using Kubernetes. It does this by being easy to use, self-explanatory, and easy to debug. Localizer only supports what Kubernetes networking does, and acts as a daemon. This is most useful when trying to expose multiple services, developers generally had to have many terminal windows to run Telepresence or other reverse tunnel solutions. Localizer moves away from that by having all commands send a gRPC message to the daemon. More on that later. At the core of Localizer is three commands.
Default: Creating Tunnels
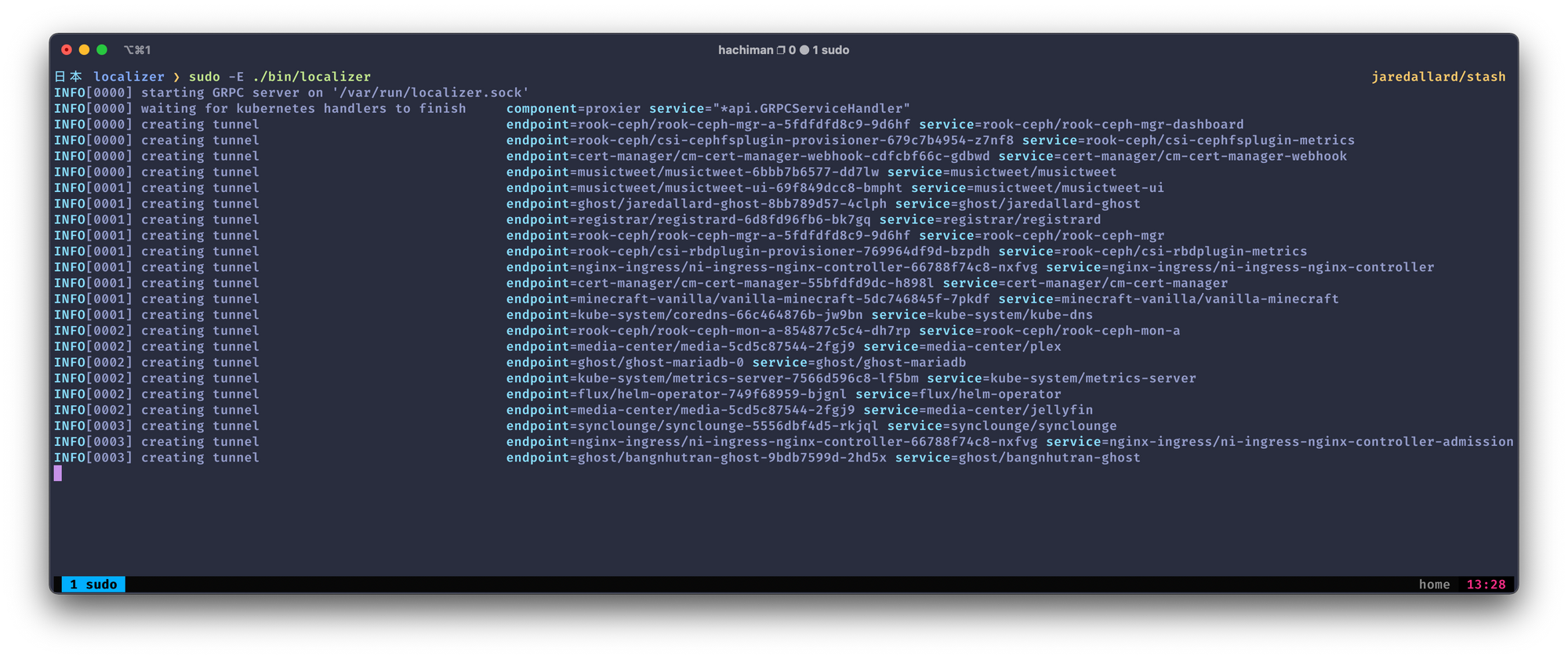
localizer on my home Kubernetes Cluster (it's not limited to just local developer environments)When you run localizer without any arguments, it automatically creates port-forwards for all Kubernetes Services (this is important), a loopback-interface powered IP address, and adds them to /etc/hosts. Out of the box, this allows code to communicate with Kubernetes services despite being outside of the cluster.
Expose: Creating a Reverse Tunnel
The expose command takes namespace/service as an argument that allows you to point a Kubernetes service down to your machine's service instance. When run, it automatically scales down any endpoints that already exist for the service. Localizer then creates an OpenSSH pod with the Kubernetes service's selector, which makes Kubernetes route traffic to the created pod. Localizer creates an SSH reverse proxy over a Kubernetes port-forward (which enables firewall bypassing for remote clusters) to the OpenSSH pod created, which exposes and routes traffic to your local service. In essence, it creates an SSH reverse tunnel for you in Kubernetes.
List: Listing the status of the tunnel(s)
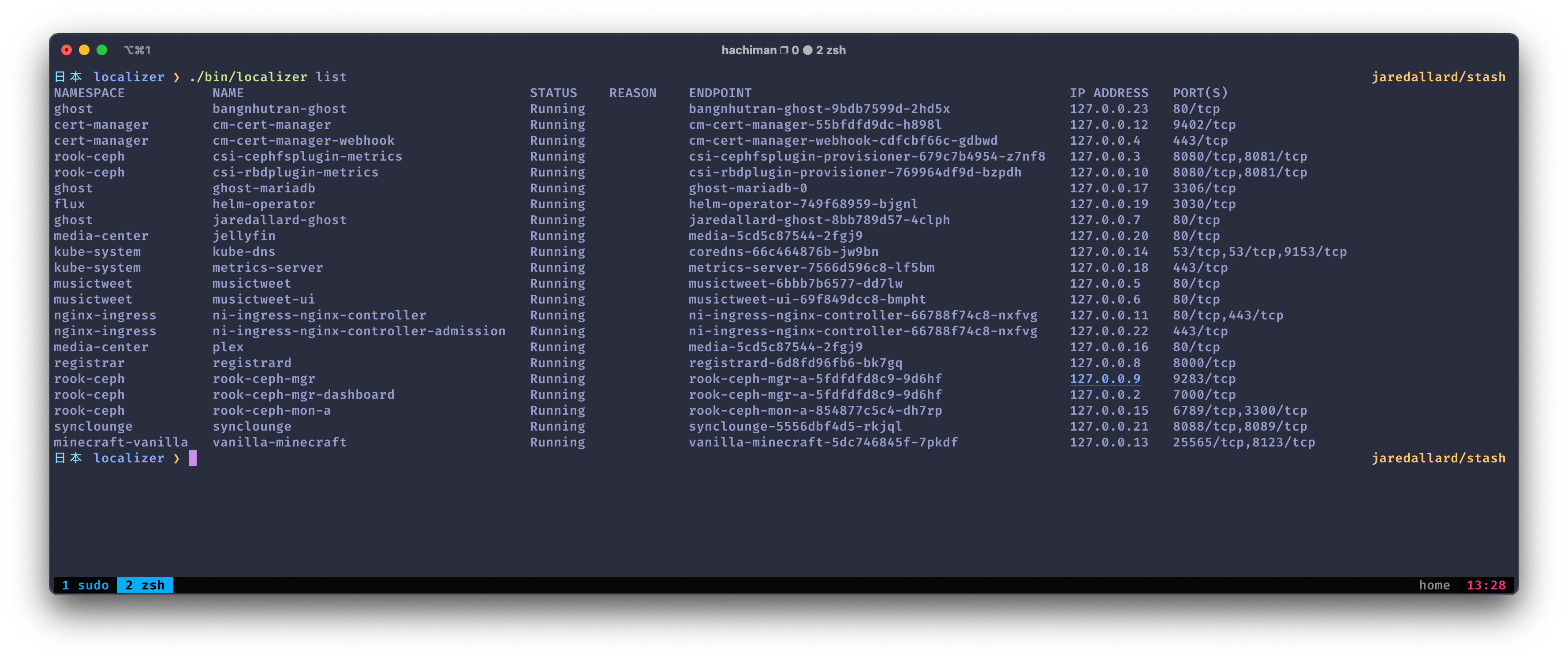
localizer list on my home cluster (Hi Ghost ?)The arguably most useful command that localizer provides is list. It enables developers to view the various tunnels running and provides insight into the health and status.
How Localizer Solved Our Problems (sort of)
Rolling out Localizer was a massive success for our developer environment's stability at Outreach, but it's ultimately not a complete solution. It helps enable the developer experience's build/test aspect, but it doesn't solve the deployment complexity aspect of Kubernetes. Ultimately, it's out of scope for Localizer to fix these problems and is just another tool that helps bridge the gap between Kubernetes and a developer's local machine.
The lack of abstractions is a fundamental problem for Kubernetes right now, and I look forward to writing tooling that can help developers focus on the business problems and not waste time on the details.
Looking to the Future
Localizer has a lot planned for the future! Namely proper daemon support, but also trying to improve the visibility into different failure modes. Stability and recoverability are going to be a constant focus for this project.
Special Thanks: Mark Lee for editing!
Questions / Comments? We don't provide a comments section on purpose, but if you have questions or comments do feel free to reach out to me on Twitter!